HTTP协议再入门
在android开发中,对应用的网络访问层做了封装,让网络访问层脱离了业务,可以在不同的应用项目中重用,在这个过程中不可避免的需要接触到HTTP协议。其实以前写前端的时候也接触到了HTTP协议的使用。不得不说,前人在这方面做了大量的工作,无论是android的Retrofit+OkHTTP或者Apache的HttpClient又或者最原始的JDK自带的URLConnection,还是前端的Ajax,这些技术的出现将计算机网络协议的复杂性都很好的隐藏在了它们自身的内部,使得外部的使用者不用关心庞大复杂的计算机网络的体系,只用使用者处理应用层的HTTP请求即可,这对开发的过程提供了极大的便利。
但同时,从学习的角度来说,由于封装的原因,在开发的过程中,我始终没有办法将代码和计算机网络的知识很好进行联系在一起。但出现需要自定义协议等特殊情况的时候,就显得比较棘手了。所以我觉得需要对整个过程进行一次梳理,以期能够对理论和实际的进行进一步的结合,提高自己对理论知识的理解。
首先我列举出我在开发中对和以前的学习中感到疑惑的问题,希望可以在后面的分析中得到解答。
1 | 整一个完整的HTTP请求的过程是怎么样的 |
流程分析
一个HTTP的事务流程就计算机网络的分层架构的完整体现。每一个层次各尽其职,保证一次数据传输的完成。
HTTP请求的逻辑过程
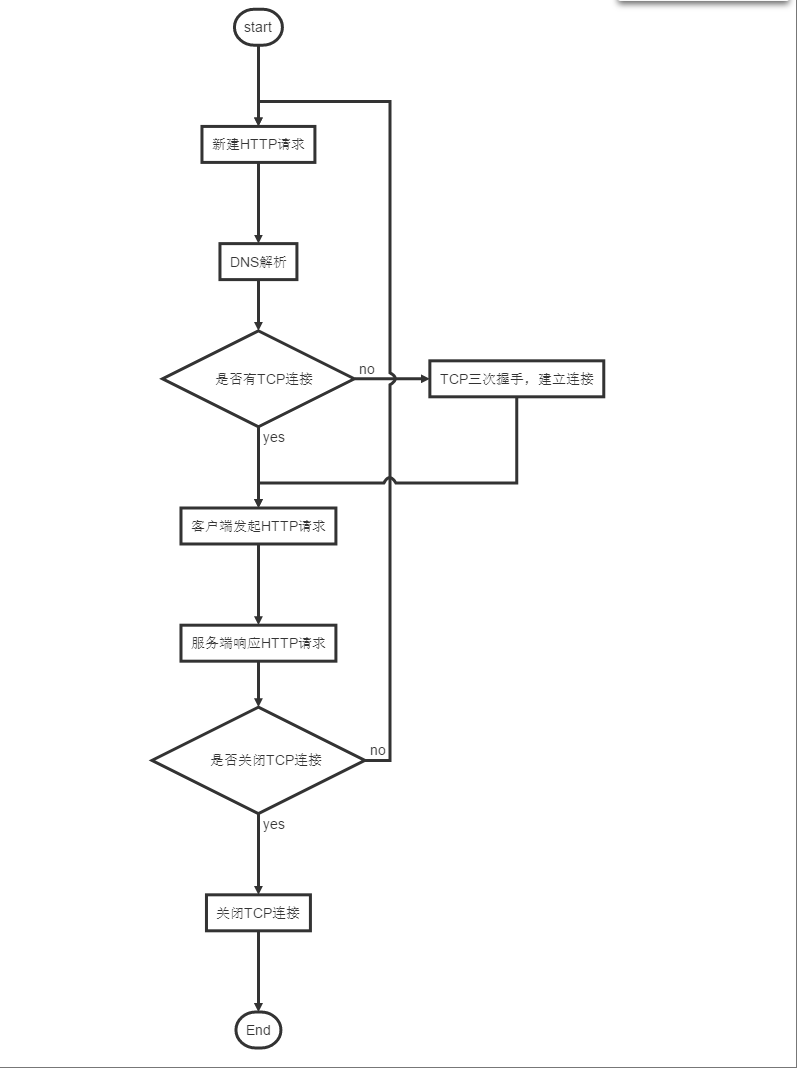
注意:在HTTP/1.0规范中,是没有持久连接的,HTTP响应后就关闭TCP连接了;在HTTP/1.1中,加入了持久连接(persistent connection),TCP连接是默认不关闭的,可以被多个请求复用。那么对于HTTP协议的无状态是指对于HTTP协议对于事务处理没有记忆能力,如果后一个请求需要前一次请求的消息,则必须重传。就像每次打电话的时候,都要从你好,找谁开始而不会直接切入主题。
HTTP请求的编程模型
上面的图表示的是HTTP请求的逻辑过程的模型,那么在实际编程中是怎么样来实现这一个过程的呢?开始的时候说了,前人已经帮我们做了大量的工作,所以现在我们只需要做的就是新建HTTP请求的工作了,其他的上面的库都已经帮我们在背后完成了。
大概的编程模型可以总结为:
| 使用层 | 应用层 | 运输层 | 操作系统 |
|---|---|---|---|
| 角色:编程人员 工作:只需要按照HTTP的规范,将HTTP的报文给构建出来即可 | 角色:HTTPClient 工作:根据HTTP的报文来新建HTTP请求 | 角色:编程接口,包括Socket,XTI/TLI 工作:提供传输层实现接口,实现运输层的连接工作 | 角色:本地调用接口(native) 工作:在系统层为通信进程分配端口,并进行绑定,同时监听请求和响应,并完成运输层后面的工作 |
URI
再来说说URI。HTTP是用来传输资源的,那么必然就需要知道如何找到资源,就好像寄快递总要知道对方的地址,打电话总要知道对方的区号和电话号码。同样的资源的标识使用的就是URI.
首先需要了解几个概念。
- IETF(Intetnet Engineering Task Force),互联网任务工程小组,负责Internet标准的开发与制定。
- RFC(Request For Comments),是一系列档案式的文档,制定了关于Internet的各种文字资料和规范,是IETF标准的主干。
URI(Uniform Resource Identifier),是RFC中的一个规范,URI的标准规范最终版是在2005年通过的RFC3986。这中间的发展过程比较曲折,说老实话,我到现在还没弄清URI成为标准的整个过程。这里先挖个坑,以后再回来填。
URI的出现,是为了对资源进行唯一标识。就好像地址一样,为了对地点进行唯一标识,但标识的方式可能不一样,可以用经纬度进行标识,也可以用官方规定的行政地址进行标识,但都可以进行唯一标识。反过来,URI中也分为两种标识方式,都可以对资源进行唯一标识。
- URL(Uniform Resource Locators):统一资源定位符,来对资源的位置进行定位,就好像经纬度一样,提供了查找资源的方法。比如,表明一个图片资源的在服务器上的目录地址。
- URN(Uniform Resource Name):统一资源名称,来对资源的进行唯一命名,就好像行政地址一样,在基于某个命名空间中通过名称定义资源的身份。比如,用于标识唯一书目的ISBN系统就是使用URN,ISBN 0-486-27557-4( urn:isbn:0-486-27557-4 )无二义性地标识出在ISBN系统这个命名空间中莎士比亚的戏剧《罗密欧与朱丽叶》的某一特定版本。
它们之间的关系如图(来源:维基百科):
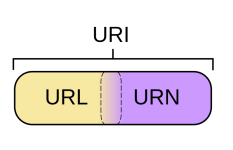
所以,无论是查找资源的唯一位置还是定义资源的唯一名称,都可以唯一表示资源。那么对于一个URI,如果是一个唯一可以获取到资源的路径,那么就是URL;如果可以唯一命名一个资源,那么是URN,如果两者都可以,那你爱叫什么叫什么。其实最好统一叫URI,因为URL的叫法正在被废除。
URI规范规定了URI的通用格式(这个得看Wiki的英文版,中文版被阉割了,下面部分翻译自Wiki,并加入部分补充):
1 | scheme:[//[user:password@]host[:port]][/]path[?query][#fragment] |
- scheme
- 作用:表示资源的访问方式或取得方式。
- 组成:规范的形式是首字母是小写字母,可以接字母,数字,
+,.,-,对于字母,尽管大小写敏感,规范的形式还是小写;schme后接:
- //
- 在某些scheme中要求,在某些scheme中不要求。当没有host部分时,就不能有
- authority part
- authention section:可选部分,由
用户名:密码@组成。是为了对一些UNIX的远程访问文件的表示方法进行统一而引入的。 - host:主机名或IP地址
- port number:端口号,和host以
:分割
- authention section:可选部分,由
- path
- 横向形式组织,用
/分割成多个部分;当没有authority part时,必须以/为首字符,也可以没有分隔符。
- 横向形式组织,用
- query
- 可选部分,和前面的部分以
?来分割,通常是用&或;做分隔符的一组key=value键值对。
- 可选部分,和前面的部分以
- fragment
- 可选部分,和前面的部分以
#来分割,通常是指向一个资源部分的片段标识符,在HTML中指的是某个DOM元素的id属性。
- 可选部分,和前面的部分以
可以参考wiki提供的例子理解
1 | hierarchical part |
这里顺便再简单了解一下资源的类型。由于由超文本变成了超媒体,所以需要对资源进行类型的分类。根据资源类型,通信双方来判断如何处理数据。
HTTP协议借鉴了电子邮件系统的设计,采用MIME(Multipurpose Mail Extension)来对资源进行分类。格式是父类型/子类型。类型的定义同样是在IETF的RCF中制定了相应的规范。
HTTP演进
- HTTP/0.9
- 原型协议;只支持
GET方法;不支持MIMIE和Header
- 原型协议;只支持
- HTTP/1.0
- 支持多媒体;增加
POST和HEAD方法;加入Header(必须是ASCII编码格式)
- 支持多媒体;增加
- HTTP/1.1
- 现在使用最多的版本;增加
PUT、PATCH、HEAD、OPTIONS、DELETE方法;引入持久连接,管道,分段,分块;
- 现在使用最多的版本;增加
- SPDY
- google自定义的协议
- HTTP/2
- 基于SPDY,与2015年发布;二进制协议,头信息和数据体都是二进制
这里就不做展开了,详细的情况可以看阮一峰的HTTP 协议入门。
HTTP报文
这一部分的内容是相当的多,看看RCF的内容就知道了HTTP/1.1。所以我觉得把所有内容列出来逐个记录不现实,最好的还是把握住整个协议的设计思路和架构,对每个部分可以建立索引,需要的时候再去查找,这样效果可能更好。这里讨论的是HTTP/1.1.
HTTP消息(报文)格式
请求消息和响应消息的结构大致相同,只是在内容上有区别。除了消息体,其他的消息部分都是纯文本,用ASCII进行编码。
- 请求行/状态行+
<CR><LF> || \r\n - 请求头部/响应头部+
<CR><LF> || \r\n - 空行(只能是
<CR><LF> || \r\n,不能有空格) 可选消息体

note:在请求头部中除了
Host是必须的外,其他的都是可选的。- 请求行/状态行+
Request Metoods
HTTP提供了八种标准的方法,区分大小写。
GET:请求资源,对应资源的查POST:提交资源,对应资源的增(如果已有则为改)PUT:更新资源,对应资源的改DELETE:删除资源,对应资源的删OPTIONS:查询服务器支持的方法,在URI部分使用*代替HEAD:请求资源,但返回的是资源的消息,对应资源元信息的查询。TRACE:回显服务器收到的请求,主要用于测试或诊断CONNECT:预留扩展,用作代理
详细方法的定义可以查看RCF关于方法的规范Method Definitions
Status Codes
HTTP的响应状态码分为五组,来更好地解释请求和响应。
- 1XX:信息状态码,表明服务端接收了客户端请求,客户端继续发送请求
- 2XX:成功状态码,表明客户端发送的请求被服务端成功接收并成功进行了处理
- 3XX:重定向状态码,表明客户端给客户端返回用于重定向地消息
- 4XX:客户端错误状态码,表明客户端地请求出错
- 5XX:服务端错误状态码,表明服务端处理请求出错
具体地状态码的定义可以查看RCF关于状态码的规范Status Code Definitions。
HTTP Headers
HTTP的Headers可以分为四种类型,用来再请求和响应中传递额外的信息。
General Headers:在请求和响应中都要应用到的但和在可选消息体(Message body)中的数据没有关系的Headers。
- Cache -Control
- Connection
- Date
- Pargma
- Trailer
- Transfer-Encoding
- Upgrade
- Via
Entity Headers:关于Message body中实体的信息,比如长度,类型
1
2
3
4
5
6Content-Encoding
Content-Language
Content-Length
Content-Location
Content-Range
Content-TypeExpires:数据的过期时间
Last-Modified:数据的最后修改时间
Request Headers:关于获取资源或客户端自身信息的Headers
Accpet
Accpet-Encoding
Accept-Language
Authoriaztion
Expect
From
Host
Referer
User-Agent
1
2
3
4
5If-Match
If-Modified-Since
If-None-Match
If-Range
If-Unmodified-SinceMax-Forwards
Proxy-Authorization
Range
TE
Response Headers:关于响应或服务端信息的Headers
- Accept-Ranges
- Age:server生产响应消息到现在的时长
- ETag:对数据进行MD5 hash计算的结果,用来检测数据是否更改
- Location:被重定向的URI
- Proxy-Authenticate
- Retry-After
- Sever:服务器标识名称
- Vary
- WWW-Authenticate
以上就是HTTP规范中对于HTTP报文格式的规范的大致内容。在实际的开发中,我们需要做的就是根据实际情况,将我们的HTTP请求按照HTTP报文格式进行组装。剩下的工作一般交给了HTTP的请求框架去。当然,如果需要一些额外的功能,就需要对框架进行扩展了。再进一步,当框架不能满足需求(其实一般不会出现,出现了可能就说明HTTP协议已经不满足需求了),这时候就要自定义协议的。就像用于流媒体,对实时性要求比较高时,所以就出现了像RTMP等这样的应用层协议了。
HTTP的再入门就到这里,接下来还需要进一步深入的点有以下几个方面:
HTTP进阶
- 验证
- 缓存
- cookie
- seesion
- 加密
- 压缩
- 长连接